The previous three articles in this series argued that distributional validation — grounded in Shannon entropy — catches a class of data quality failure that schema validation, freshness monitoring, and rule-based constraint checks structurally cannot. The first article laid out the mechanism. The second validated the mechanism against nearly 6.6 million rows of real-world data in a preregistered benchmark. The third applied the evidence to semantic-layer architectures.
Read together, those three articles carry an implicit framing that is worth examining directly: a drop in entropy is a warning. The benchmark article reported perfect drift-detection sensitivity on injected distributional shifts. The semantic-layer article then described how an entropy drop in a filter column can silently inflate a governed metric. The takeaway an attentive reader walks away with is straightforward: when entropy falls, something is probably wrong.
That framing is true often enough to be useful. It is also incomplete. Entropy drops happen in production systems all the time, and in a meaningful fraction of cases, the drop is not a signal of failure — it is a signal that the system is doing what it was designed to do. A conversion funnel that filters correctly produces entropy drops. A fraud classifier whose prediction distribution tightens after retraining produces entropy drops. A compliance rule that tightens produces entropy drops. A seasonal sales event that narrows the product mix produces entropy drops. In each case, the drop is the system working.
A drift-detection layer that cannot tell the difference will either produce too many false alarms and get tuned out, or — more dangerously — get its thresholds raised until it silently tolerates real collapses alongside the legitimate convergences. Neither outcome is acceptable. The harder problem, and the subject of this article, is distinguishing entropy collapse (unintended information loss that invalidates downstream metrics) from entropy convergence (intended concentration that reflects the system performing its designed function).
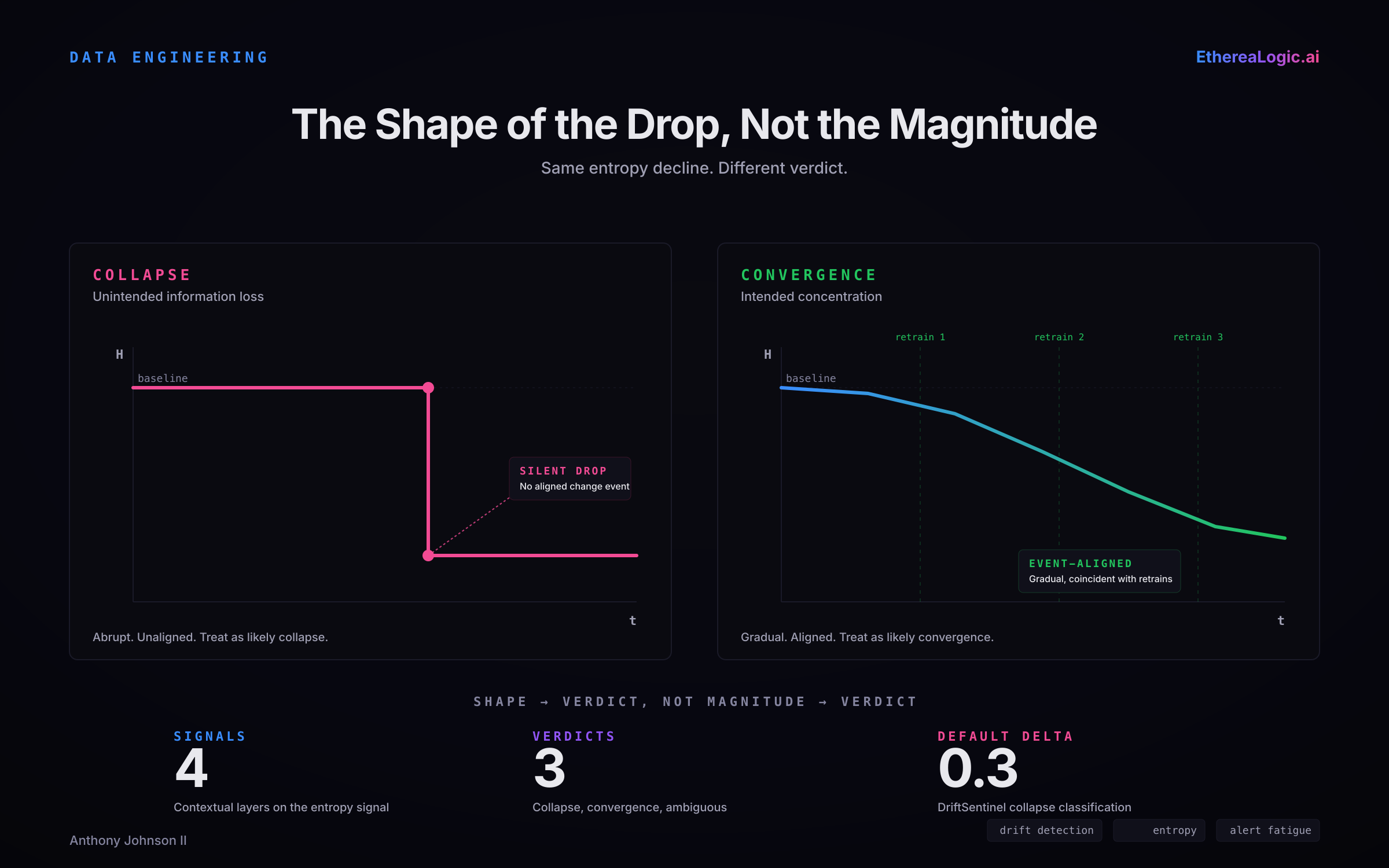
Same magnitude of entropy drop. Different shape. Different verdict. The shape of the drop — abrupt and unaligned versus gradual and event-aligned — is a first-order signal for distinguishing collapse from convergence, before any of the other contextual signals are evaluated.
The Two Failure Modes of a Naive Entropy Alert
A drift-detection layer that alerts on every substantial entropy drop runs into two predictable failure modes.
The first is alert fatigue. In a data platform with hundreds of monitored columns across dozens of pipelines, legitimate entropy changes occur daily. Every customer-segmentation refresh, every A/B test rollout, every seasonal merchandising change, every classifier retrain produces at least one column whose entropy moves. A monitoring layer that treats each of these as an incident will generate more alerts than the team can triage. Within weeks, the alerts are treated as noise, the channel is muted, and the capability becomes decorative.
The second is threshold inflation. A team that recognizes the alert-fatigue problem typically responds by raising the entropy-drop threshold until the alert volume is tolerable. The side effect is that the threshold is now insensitive not only to benign convergences but to the class of failure the detector was installed to catch. Real collapses can present with magnitudes near the default detection thresholds — the DriftSentinel default cited in the third article, a normalized-stability delta of 0.3, sits well within the range that an anti-fatigue threshold raise would suppress.
Both failure modes share a root cause: they treat entropy as a scalar alerting signal rather than as one dimension of a contextual judgment. The fix is not to change the threshold. The fix is to add the context that distinguishes collapse from convergence.
Four Canonical Cases of Convergence That Should Not Alert
Before discussing the distinguishing signals, it helps to make the convergence class concrete. These four patterns produce substantial, durable entropy drops in real production systems. All four are the system working as designed.
Conversion-funnel progression. A SaaS onboarding funnel logs an onboarding_stage column across the user lifecycle, where each user’s value records the latest stage they reached. Early in the observation window, the column takes many values with a relatively spread distribution — landing_visited, email_entered, trial_started, plan_selected, payment_attempted, activated, abandoned. Late in the lifecycle window, once most users have hit a terminal state, the column is dominated by activated with a residual abandoned tail. Entropy drops materially between the early-window and late-window distributions. The drop is the funnel working. A distributional-validation layer that alerts on the late-window cohort against an early-window baseline is comparing the wrong populations.
Classifier output-distribution shift. A fraud-detection model is retrained quarterly. Early in the model’s life, its predicted_label output distribution is roughly 88% legitimate and 12% flagged. After two retraining cycles, the distribution tightens to 96% legitimate and 4% flagged. Entropy drops. The proportion shift on its own does not prove the model improved — it could equally reflect a drift in the underlying fraud rate or a loss of sensitivity — so the question is not what the distribution did, but what the downstream quality metrics did alongside it. If outcome-based evaluation metrics continue to hold — false-positive review backlog stable, true-positive recall stable, precision confirmed against labeled ground truth — the entropy drop is a benign consequence of a legitimate retraining event, not a data-quality failure. If those downstream metrics degrade, the entropy drop is a symptom of a real regression that needs to be investigated regardless of its cause. The entropy drop alone does not distinguish the two cases; the downstream evidence does.
Business-rule tightening. A compliance filter that historically admitted five customer tiers (free, starter, professional, business, enterprise) is narrowed by a policy change to admit only business and enterprise. The downstream active_customer_tier column, measured on the filtered population, narrows from five values to two. Entropy drops by a large margin. The drop reflects a governance decision, not a breakdown.
Seasonal concentration. A retailer runs a clearance window during which the merchandising system intentionally narrows the active SKU catalog from 12,000 to 3,500 items. The sku_id column on same-day transactions shows a substantial entropy drop across the clearance window. The drop is expected, planned, and aligned to a specific calendar event. A baseline computed against non-clearance weeks will flag every clearance day as an anomaly.
Each of these cases produces entropy signatures that, in isolation, look like the collapse signatures described in the earlier articles. The distinguishing information is not in the column itself. It is in the context around the column.
The Distinguishing Signals
A distributional-validation layer that handles convergence correctly layers four kinds of context on top of the raw entropy signal. None of them require proprietary machinery. All of them require that the validation layer be wired into information that already exists in most data platforms.
Cardinality-shape signature. Collapse and convergence produce different cardinality signatures. In a typical collapse, the column’s distinct-value count drops — one or more values disappear from the distribution, either because upstream logic stopped producing them or because a remapping absorbed them into another value. In a typical convergence, the distinct-value count is preserved, and the change shows up as a re-weighting of existing values rather than as a loss of values. A starter customer tier that disappears entirely has a different signature from a starter tier whose share shrinks from 20% to 5%. Not every real case is clean — a convergence can legitimately eliminate a rare value, and a collapse can occasionally preserve all values at shifted proportions — but the cardinality signature is an inexpensive first-order signal that re-weights the prior probability of collapse versus convergence.
Change-event alignment. Most production data platforms produce a timeline of change events: dbt model deployments, pipeline configuration changes, classifier model version bumps, merchandising policy changes, compliance rule updates. An entropy drop that is aligned to a known change event is strong prior evidence of convergence. An entropy drop that arrives silently, with no coincident change event, is stronger prior evidence of collapse. Platforms that capture a clean change log — even a lightweight one — gain a disproportionate amount of signal here, because the alignment test is cheap and the prior it shifts is large.
Downstream-coherence check. The purpose of distributional validation is to protect downstream metrics. A column whose entropy has moved, but whose downstream KPI is still tracking its expected target within its normal variance, has usually experienced a convergence. A column whose entropy has moved and whose dependent KPI shifts in a way consistent with the metric definition, lineage, and observed distributional change has stronger evidence of collapse. This is the most expensive of the four signals to evaluate, because it requires a materialized link between the column and the KPIs that depend on it — entropy alone does not predict the direction or magnitude of KPI movement; that prediction comes from the metric definition combined with the entropy signal. It is also the most diagnostic when the link exists.
Temporal signature. Collapse tends to be abrupt. An upstream system changes its default assignment logic at 3:14 AM and the entropy signature for the affected column shifts within a single batch. Convergence tends to be either gradual — a classifier improving over multiple retraining cycles — or sharply event-aligned to a scheduled boundary like a deployment window or a clearance start. A drop that is both abrupt and unaligned to any known change event should be treated as a likely collapse. A drop that is either gradual or cleanly aligned to a known event boundary should be treated as a likely convergence pending the other signals. The temporal pattern is a relatively weak signal on its own, but it is nearly free to compute and combines well with the others.
None of these four signals is individually sufficient. In combination, they shift the distributional-validation layer from a binary alerting signal to a contextual verdict that a human operator or downstream automation can act on. The second article in this series reported that the raw entropy signal achieved sensitivity of 1.0 and a false positive rate of 0.0 on drift detection across three datasets, and precision and recall of 1.0 on a distinct quality-validation task against a rule-based baseline. Those results describe the behavior of the measurement layer. The practical question that remains is how to preserve the measurement’s accuracy while filtering out the convergence class — and the answer, in the systems I have built and operate, has been context layering rather than threshold inflation.

The cardinality signature and change-event alignment, combined, produce four distinct contextual verdicts with specific operator actions. A reduction in cardinality alone does not prove collapse — the verdict depends on whether a known change event explains it. The ambiguous quadrant is diagnostic rather than apologetic: it flags the cases where the two first-order signals disagree and human review is genuinely needed, rather than forcing those cases into a binary call that the thresholds, not the evidence, would decide.
Why the Distinction Matters at the Semantic Layer
The third article in this series argued that semantic layers need distributional validation on their filter columns because metric definitions are implicitly functions of those distributions. The collapse-versus-convergence distinction changes what that validation layer should actually do when it fires.
Consider a governed semantic-layer metric like monthly_recurring_revenue, filtered on subscription_status = 'active' and grouped by customer_segment. If customer_segment shows an entropy drop because an upstream CRM migration silently remapped tier logic, that is a collapse, and the correct response is to gate the metric until the anomaly is investigated. If the same column shows an entropy drop because the sales team executed a planned consolidation from five tiers to three — documented in a change log, aligned to a specific deployment window, with downstream pipeline contracts updated in advance — that is a convergence, and the correct response is to update the baseline against which future distributions are measured, not to gate the metric.
A validation layer that cannot tell the two cases apart will either block legitimate metric evolution (if it errs on the side of caution) or silently tolerate real failures (if it errs on the side of throughput). Neither is acceptable for a governed metric. The collapse-versus-convergence distinction is what makes distributional validation at the semantic-layer boundary operationally workable rather than theoretically interesting.
The same logic applies to coherence scoring across the Medallion architecture. AetheriaForge’s configurable layer-specific coherence thresholds — operating defaults of Bronze greater than or equal to 0.5, Silver greater than or equal to 0.75, Gold greater than or equal to 0.95 — are designed to detect transformations that destroy information content unexpectedly. A transformation that legitimately narrows its input — a filter stage, a classification stage, a business-rule application — will produce a coherence score lower than an identity transformation would. That is the transformation working. The distinction between a coherence drop that reflects a working transformation and a coherence drop that reflects a broken transformation is the same distinction discussed here, applied at a different architectural layer.
Facts
The following are measured facts drawn from the preregistered benchmark artifacts referenced in the second article in this series and the public articles summarizing those results. They should be read within the scope boundaries of those experiments.
- The preregistered benchmark program referenced in the second article achieved drift sensitivity of 1.0 and a false positive rate of 0.0 across three independent real-world datasets — OpenML Adult Income (32,561 rows), NYC TLC Yellow Taxi (3,066,766 rows), and U.S. Census ACS PUMS (3,500,000 rows).
- Quality validation on the same benchmark achieved precision and recall of 1.0 on all three datasets, against a rule-based baseline that dropped to precision 0.6 and F1 0.75 on the most distributionally complex dataset.
- Cross-machine reproducibility was 60 out of 60 matched gate verdicts with bitwise-identical non-latency metrics.
- AetheriaForge’s coherence-scoring operating defaults — Bronze greater than or equal to 0.5, Silver greater than or equal to 0.75, Gold greater than or equal to 0.95 — are documented in the third article of this series as configurable per data contract and should be treated as AetheriaForge defaults, not Databricks-prescribed standards.
- The DriftSentinel collapse classification threshold referenced in the third article applies when the delta between current normalized stability and baselined stability exceeds a configurable default of 0.3.
Interpretation
The following are engineering judgments drawn from operating distributional-validation systems against real workloads. They should be read as claims about the author’s experience, not universal prescriptions.
The collapse-versus-convergence distinction is the single highest-leverage refinement a team can make to a distributional-validation deployment after the raw detection is working. Teams that get the raw detection working but do not make this distinction experience one of the two naive failure modes — alert fatigue or threshold inflation — often within weeks of going live. The cost of the distinction is moderate (four new contextual signals to wire in). The payoff compounds quickly.
Of the four contextual signals, change-event alignment is the most cost-effective. A lightweight internal change log — dbt deployment timestamps, pipeline-configuration commit SHAs, classifier-retraining events — that the validation layer can query shifts the prior probability of convergence decisively when an entropy drop lines up with a known event. Teams that do not already produce a change log should instrument one before investing in more sophisticated baseline-adaptation strategies.
Downstream-coherence checking is the most diagnostic signal but the most expensive. It requires a materialized link between each monitored column and the specific KPIs that depend on it. Most data platforms do not have this link documented. When the link exists, it is usually worth the cost — a coherence check that shows “this column’s entropy changed and the KPI that depends on it is tracking fine” resolves many ambiguous cases without human review. When the link does not exist, starting with cardinality-shape and change-event alignment is the more pragmatic path.
A distributional-validation layer that reports collapse, convergence, and ambiguous as three distinct verdicts — rather than collapsing everything into a binary alert — produces dramatically more actionable operator output. The ambiguous class is not a failure of the system; it is an accurate acknowledgement that some entropy drops genuinely cannot be classified without human context. An operator given “ambiguous, please review” with the cardinality signature, the coincident change events, and the downstream-coherence state is equipped to triage. An operator given “alert, threshold breached” is not.
The broader claim made by the three prior articles in this series — that schema validation, freshness monitoring, and rule-based constraint checks leave a distributional-validation gap — is strengthened rather than weakened by the convergence analysis. The concern a skeptical reader might raise (“doesn’t entropy drop all the time for legitimate reasons, and wouldn’t that make the alerting noisy?”) is real. The answer is not that the concern is wrong, but that the distributional-validation layer is not a naive alerting system. It is a contextual judgment built on top of a well-characterized measurement. The measurement remains as evidenced as the second article claimed. The judgment on top of it is what this article is about.
Practical Implications for Enterprise Teams
If your distributional-validation layer is in production and generating too many alerts, the first diagnostic is whether the alerts correspond to collapses or to convergences. If the majority of alerts trace back to legitimate business events — deployments, model retrains, policy changes, seasonal windows — the correct response is to add the contextual signals described above, not to raise the threshold. Threshold inflation degrades the detector’s ability to catch the collapses it was installed to catch.
If your platform does not produce a machine-readable timeline of change events, producing one is a high-leverage investment. The change-event alignment signal is cheap to compute and strongly diagnostic, but only if the events themselves are captured. Even a lightweight change log that captures deployment timestamps, configuration commits, and model-version bumps is usually sufficient.
If your distributional-validation layer produces a single binary verdict, consider extending it to a three-way verdict that distinguishes collapse, convergence, and ambiguous. The ambiguous class is where the real value sits — it is where the system honestly reports that human context is needed. A system that forces every case into collapse or convergence will misclassify some meaningful fraction of ambiguous cases, and the direction of the misclassification will depend on where the thresholds sit rather than on the underlying truth.
If you are building a distributional-validation capability for the first time, plan for the convergence analysis from the start rather than bolting it on later. The raw detection layer and the contextual-judgment layer are easier to design together than to retrofit. Teams that ship the raw detection first and add context later spend an extended period in a half-trusted, half-ignored state while operators learn to mistrust the alerts before the context layer arrives to justify them. Teams that ship the full stack together skip that phase entirely.
This is the fourth article in the EthereaLogic distributional-validation series. The three prior articles established the mechanism, the evidence, and the semantic-layer application. This article addresses the operational refinement that determines whether a distributional-validation layer is sustainable in production.