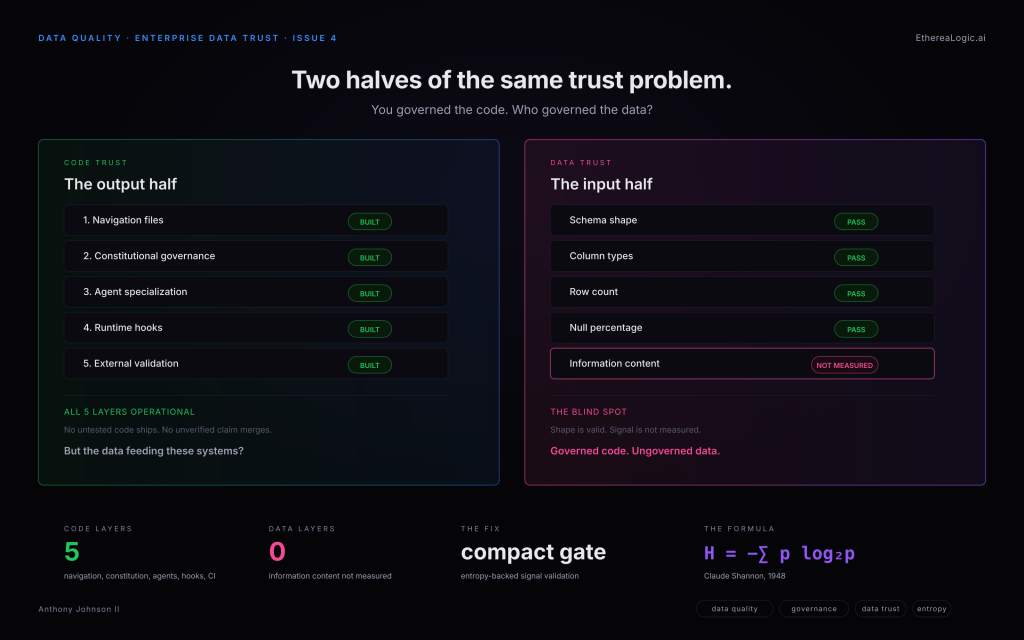
Your governance stack is working. The hook blocks the agent from pushing to a protected branch. CI confirms the tests pass independently. Branch protection closes the merge path. Static analysis flags complexity. Dependency scanning checks every package against a live vulnerability database. No untested code ships. No unverified claim merges.
And this morning, the governed system made a decision based on a customer_tier column that had silently lost half its information content. The segmentation model downstream — the one your agent calls to classify accounts — still assumed a four-tier baseline that no longer existed in the data. Revenue forecasting diverged from actuals by 12%. The Customer 360 that was supposed to unify 40,000 accounts quietly deduplicated to 24,000.
Every governance layer held. The data underneath all of them did not.
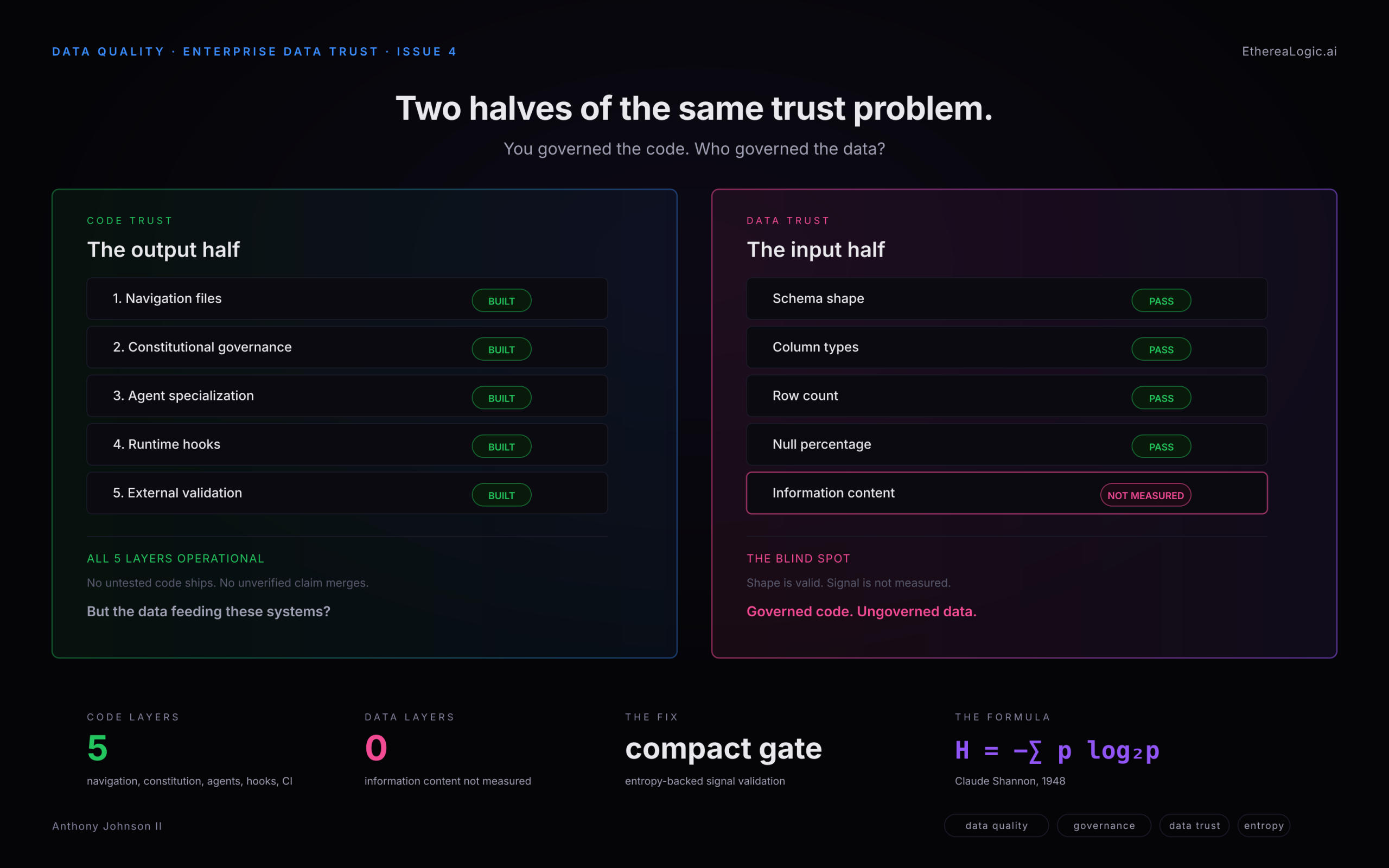
The code-output side of the trust model is governed. The data-input side is still mostly structural checks — schema, row count, freshness — with no measurement of whether the signal survived.
The first three issues of Enterprise Data Trust built the case for a five-layer governance stack — the architecture that lets a regulated business trust code an AI agent wrote. Issue #1 laid out the full stack. Issue #2 went inside runtime enforcement — the hook that stops a forbidden action before it lands. Issue #3 closed the loop with external validation — the independent check that treats the agent’s self-report as a claim, not a conclusion. That stack is the output half of the trust problem. This issue is the input half.
The half you solved
The governance stack governs what the agent produces. Each layer answers a question the layer above it cannot:
Navigation files tell the agent where things are. The constitution tells it what principles to follow. Agent specialization scopes its role. Runtime hooks block forbidden actions at the moment of execution. External validation confirms the result independently.
Together, the five layers create a system where a capable agent, moving fast, with confirmation prompts off, cannot ship code that violates the rules the organization agreed on. The hook exits 2 and the action never lands. CI disagrees and the merge is blocked. The operating envelope is structural, not advisory.
That is a genuine engineering achievement. It is also only half the problem.
The half you haven’t
Every layer of the governance stack assumes the data feeding the system is trustworthy. The hook that blocks a push to main says nothing about whether the production data the agent’s model depends on has drifted. The CI run that confirms test correctness says nothing about whether the customer_tier column the segmentation logic depends on still carries four meaningfully distinct values. The branch protection that closes the merge path says nothing about whether the entity-resolution pipeline upstream has started over-merging 40,000 accounts into 24,000.
Your governance stack will faithfully enforce every rule on code that is making decisions on data nobody measured.
This is not a hypothetical. Most data quality monitoring validates shape — schema, types, row counts, null percentages, freshness. These are necessary checks. They tell you whether data arrived in the expected structure. They do not tell you whether the data still carries the information it carried yesterday.
A column can go from 12 distinct categories to 8, and every traditional check passes. A distribution can shift from uniform to heavily skewed, and row counts will not flinch. A source table can silently converge to a single dominant value, and your freshness monitor will report on time. The shape is valid. The signal is gone.
What ungoverned data looks like in practice
The governance stack vocabulary makes the gap concrete. Consider three failure modes through the lens of the controls you already built:
Your hook stopped the agent from pushing to main. Nothing stopped a collapsed distribution from reaching the model the agent is calling. A region field that once carried 12 values starts arriving with 8. An order_type concentrates from evenly distributed to 90% dominated by a single value. Schema is unchanged. Row count is stable. The model downstream makes systematically different decisions — and the governance stack, which governs the code path, has no visibility into the data path.
Your CI confirmed the tests pass. Nothing confirmed that the transformation preserved the information it was supposed to. A Bronze-to-Silver pipeline applies 14 transformations. The output schema matches. Types are correct. But a join condition was too aggressive, and 26% of the distributional information in your key segmentation columns was destroyed in the transformation. Your CI pipeline validated the code. Nobody validated the data.
Your branch protection closed the merge path. Nothing closed the path for entity-resolution drift. Your Customer 360 resolved 40,000 source records into 32,000 unified entities last quarter. This quarter, the same source count resolves to 24,000. Is that more legitimate duplicates, or matching logic that has drifted toward over-merging? Without measuring the information content of entity keys before and after resolution, you cannot distinguish the two — and your governance stack has no opinion on the question.
Each of these failures is invisible to every layer of the governance stack. Not because the stack is flawed, but because it was designed to govern a different surface.
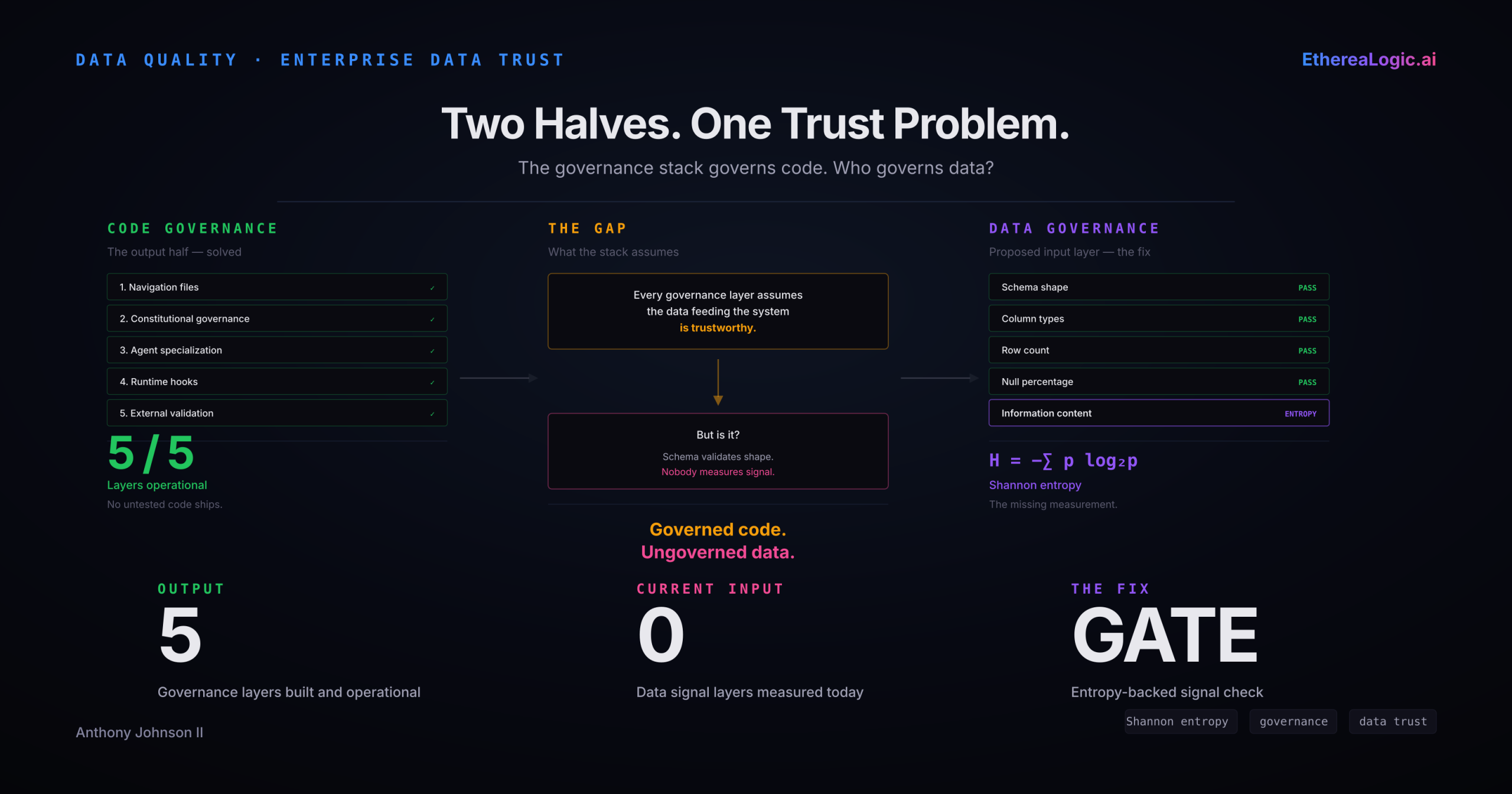
The same governance logic that makes code outputs trustworthy has to extend upstream. Hooks and CI close the code path; entropy-backed validation closes the data path.
The measurement that closes the gap
An entropy-backed drift gate is the data-side analog of the hook. Shannon entropy — Claude Shannon’s 1948 measure of information content — is the measurement underneath that gate. Where a hook sits at the boundary between intent and action for code, an entropy gate sits at the boundary between structure and signal for data.
The measurement is not expensive. It is a compact calculation: a normalized stability score between 0.0 and 1.0, comparable across columns of any cardinality, computable at ingestion time. The engineering cost of adding it is hours — the same order of magnitude as wiring the first hook.
A customer_tier column with four evenly distributed values carries 2.0 bits of entropy — maximum for four values. If that column collapses to one dominant value, entropy drops to 0.987 bits, and the stability score falls to 0.494. Schema check still passes. Row count still matches. But any model, any segmentation rule, any pricing algorithm trained on the baseline distribution is now operating on fundamentally different data.
Schema validation is not wrong. It answers a necessary question. Entropy answers the question schema cannot: does the data still carry the information it carried yesterday? You need both — the same way you need both the hook and CI. Each catches what the other structurally cannot.
What this means for your team
If you built the governance stack — or any part of it — you already understand the principle. A rule is not a control. A document is not enforcement. Intent without a mechanism at the boundary is a wish.
The same principle applies to data. A schema check is not a signal check. A row count is not an information-content measurement. Structural validity without distributional validation is the data-side equivalent of a governance policy without a hook: it describes the boundary without sitting at it.
The trust model is incomplete until it covers both halves. The governance stack is the output half — it ensures the agent cannot ship ungoverned code. Distributional validation is the input half — it ensures the agent is not making decisions on ungoverned data. Extending the model starts with the same class of engineering investment that wired the first hook.
The full technical breakdown — the entropy formula, the customer_tier example, four failure modes, the drift-gating workflow, and the coherence-scoring pattern across Medallion layers — is on the EthereaLogic blog. This issue is the executive frame.
Next time, Enterprise Data Trust goes from theory to evidence: the experiments across 6.6 million rows and three independent datasets that show the margin between entropy-based monitoring and traditional tools is not small.
— Anthony